状態変数のフィードバック
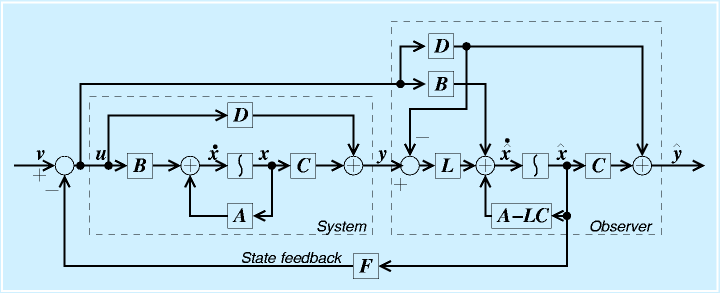
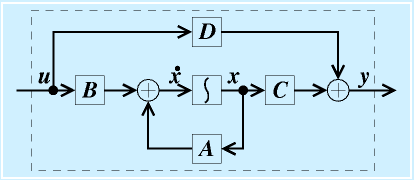 状態方程式で表したシステム
状態方程式で表したシステム
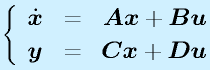
をブロック線図で表すと、右図のようになります。
古典制御理論では、全体の出力 y を入力に対してフィードバックしました。それに対して、状態制御論におけるフィードバックは、状態変数をフィードバックします。これを状態フィードバックと言います。
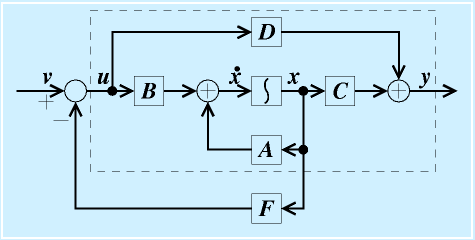 具体的には、システムの入力 u に対して、
具体的には、システムの入力 u に対して、
![]()
を入力します。 v は u に代わる、新しい入力です。
これを元のシステムの状態方程式、出力方程式に代入します。
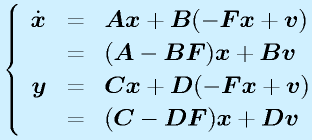
この式を良く見ると、元々 A だったシステム行列が A-BF に置き換えられたシステムになったと見ることができます。
なお、(A,B)が可制御ならば(A-BF,B)も可制御、(C,A)が可観測ならば(C-DF,A-BF)も可観測です。
状態フィードバックと固有値
システムの安定性(収束性)が、システム行列の固有値に依存することはすでに説明しました。特に固有値の実部が負でなければ、そもそも不安定です。
ここでは状態フィードバックによる固有値の変化を調べてみます。
もとのシステムの固有値は、特性方程式
![]()
で得られます。状態フィードバックしたシステムの固有値は、
![]()
の解です。
ここでは、1入力1出力、2次のシステムを例にその固有値の変化を考えてみます。
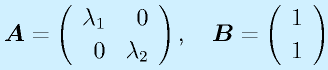
![]()
とすると、
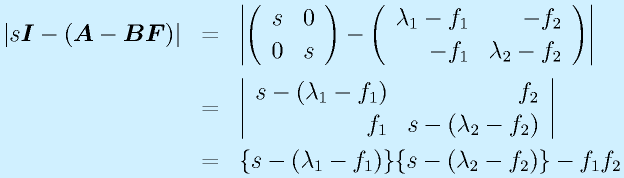
![]()
ここで、
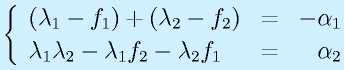
とおくと、
![]()
となります。
一方、

なので、λ1≠λ2ならば、α1、α2を指定すれば、f1、f2を求められます(可制御なら、λ1≠λ2)。
よって、
- 目標とする固有値を決める
- α1、α2が求まる ※(s-λ1)(s-λ2)=0より
- f1、f2を求める
状態フィードバックを行うと、可制御なら 元のシステムが不安定であっても安定化 し、かつ収束の特性も決めることができます。
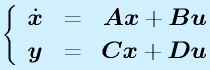
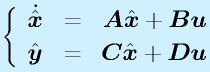
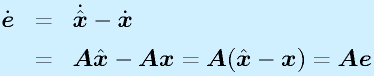
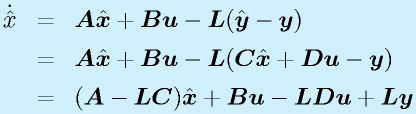
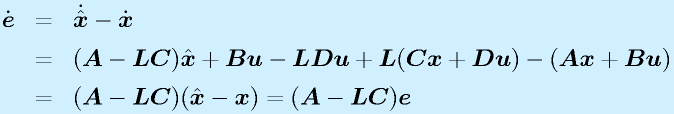
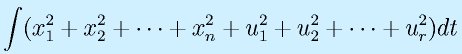
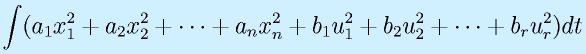
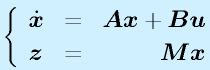 (z: 仮想的出力)
(z: 仮想的出力)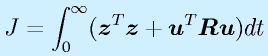
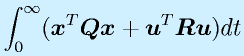
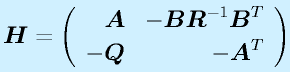 (2n×2n)
(2n×2n)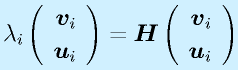
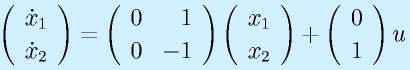
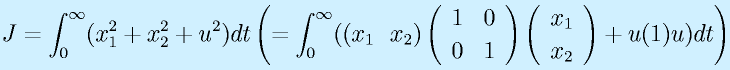
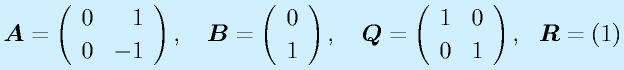
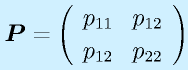 (正定対称)として、
(正定対称)として、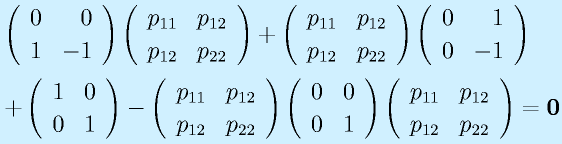
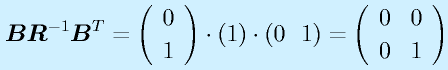
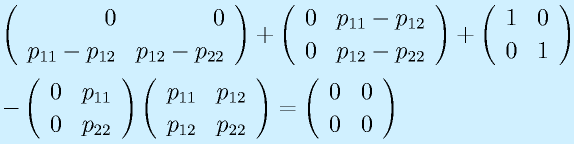
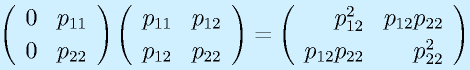
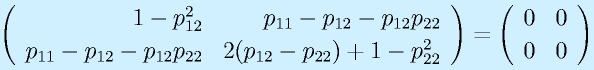
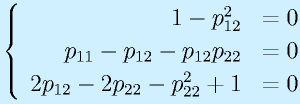
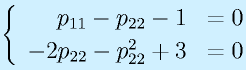
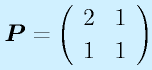
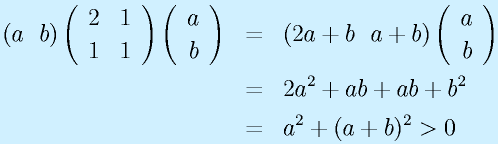
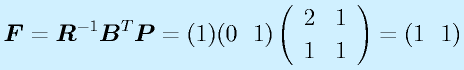
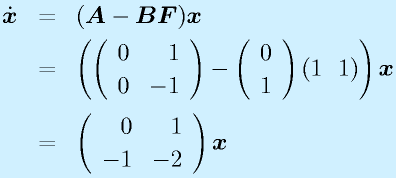
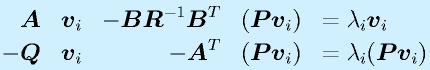
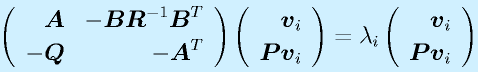
![\vect{P}[\vect{v}_1~~\vect{v}_2~~\cdots~~\vect{v}_n]=[\vect{u}_1~~\vect{u}_2~~\cdots~~\vect{u}_n]\nonumber\\\vect{P}=[\vect{u}_1~~\vect{u}_2~~\cdots~~\vect{u}_n][\vect{v}_1~~\vect{v}_2~~\cdots~~\vect{v}_n]^{-1}](eqn/statefeedback.bhtml.eqn110.gif)
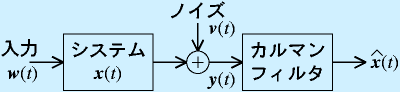 推定する対象となるシステムには、センサで観測するときにノイズが混じっているものとします。また、入力は任意で、何が入るかわからないとします。
推定する対象となるシステムには、センサで観測するときにノイズが混じっているものとします。また、入力は任意で、何が入るかわからないとします。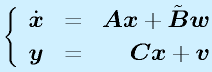
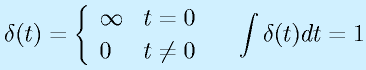
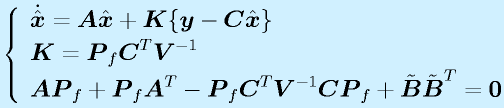
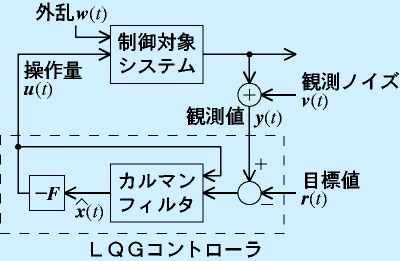 LQG(Linear-Quadratic-Gaussian)コントローラは最適制御とカルマンフィルタを合体させたフィードバック制御系です。
制御対象の出力からカルマンフィルタで状態変数を推定し、それで状態フィードバックをかけます。
LQG(Linear-Quadratic-Gaussian)コントローラは最適制御とカルマンフィルタを合体させたフィードバック制御系です。
制御対象の出力からカルマンフィルタで状態変数を推定し、それで状態フィードバックをかけます。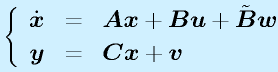
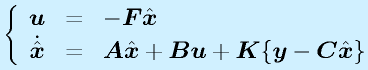 (最適制御/カルマンフィルタ)
(最適制御/カルマンフィルタ)