まずは試してみるのが、一番分かりやすいかと思いますので、最初から実験です。
この実験は常識の範囲では、コンピュータが落ちたりすることはありませんのでご安心を。
まずはソースリストです。時間計測にgettimeofdayをつかいます。
Linuxではこの関数はマイクロ秒オーダの分解能があるようです。
Pentium以降のCPUを持ったパソコンで試す場合は -DUSE_RDTSC をつけてコンパイルすると、
Pentium 以降のCPUで装備されたRDTSC という、リセット時からのCPUクロックの数を数える命令をつかって時間を計ります。
TickPerMSec には CPUの動作周波数を1000で割ったくらいの数字を書いておけば、だいたいの精度はでます。
#include <stdio.h>
#include <sys/time.h>
#include <unistd.h>
#include <stdlib.h>
#include <math.h>
#define TestCount 1000
#ifdef USE_RDTSC /* Pentium 以降のRDTSC命令を使用 */
/* 1秒あたりの 1 tick */
#define TickPerMSec 200e3 /* CPU の周波数に依存: だいたい公称値 */
/* 現在時間取得: 単位 tick */
unsigned long long GetTick(void)
{
unsigned int h,l;
/* read Pentium cycle counter */
__asm__(".byte 0x0f,0x31" : "=a" (l),"=d" (h));
return ((unsigned long long int)h<<32)|l;
}
#else
/* 1秒あたりの 1 tick */
#define TickPerMSec 100.0
/* 現在時間取得: 単位 tick */
unsigned long long GetTick(void)
{
struct timeval tv;
gettimeofday(&tv,NULL);
return (unsigned long long)tv.tv_sec*1000000+tv.tv_usec;
}
#endif
int main(int argc,char **argv)
{
int cycle=15;
int i,j;
double a=1;
FILE *fp;
unsigned long long ticks[TestCount];
if(argc>1) cycle=atoi(argv[1]);
for(i=0;i<TestCount+3;i++) /* 一定周期ループ */
{
/* 計測 */
if(i>2) /* 最初は絶対ずれるからパス */
ticks[i-3]=GetTick();
else
GetTick(); /* 空読み */
/* ダミー処理 */
for(j=0;j<100;j++) a=sin(cos(a));
/* 休止 */
usleep(cycle*1000); /* msec->usec */
}
fp=fopen("cycle.xy","w");
for(i=0;i<TestCount-1;i++)
{ /* number, interval, time */
fprintf(fp,"%d\t%lf\t%lf\n",i,
(ticks[i+1]-ticks[i])/TickPerMSec,
(ticks[i]-ticks[0])/TickPerMSec);
}
fclose(fp);
return 0;
}
このプログラムを
gcc -o cycle cycle.c -lm
などとコンパイルし、実行すると、しばらく(20-30秒)して cycle.xy というファイルができます。
その一例を示します。これはあくまで一例です。
環境に依存しますし、二度と同じ結果はでません。
また、Linux 2.0 では周期が30[ms]になるようです。
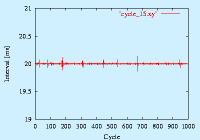 このプログラムは 引数を指定するとその時間([ms])だけ休むようになっています(usleep)。
デフォルトでは15[ms]です。この数値を変化させて結果を取ってみると以下のようなことがわかります。
このプログラムは 引数を指定するとその時間([ms])だけ休むようになっています(usleep)。
デフォルトでは15[ms]です。この数値を変化させて結果を取ってみると以下のようなことがわかります。
- ときどき遅れることがあるが、基本的にはある周期で
精度良く実行を繰り返す
- いくら数値を小さくしても、20[ms]より短くなることはない。
- いくら数値を変化させても、周期は10[ms]単位である。
(Alpha用Linux以外の PC-AT系、LinuxPPC、Sparc などの場合、Linux2.6以降はx86でも1ms単位?)
いくらか周期設定に制限はあるようですが、その周期そのものはフィードバック制御などにはそこそこつかえます。
つまり、いまのままでも、周期 20[ms] でよければ、すぐに制御に使えます。
より間隔を短く&細かく設定したい場合には、Linuxのソースを数文字変更(0をひとつ足すなど)すれば希望通りになります。
その話のまえに、Linuxカーネルの動作の解析をしておきます。いわば、本手法の原理にあたる部分です。
なんでもいいから早く試してみたいという方は、カーネルソースを再構築用に展開し
(各ディストリビューションのマニュアルをご確認下さい)、
/usr/src/linux/include/asm/param.h
の HZ という数値の定義を 100 から1000 にして再構築し、そのカーネルで起動してみてください
(モジュールの再構築、インストールも必要)。
2[ms]以上, 1[ms]単位で周期が決められるようになっているはずです。
Linux とプロセス
Linux では 多くのUNIX系のOS同様、プログラムの実行をプロセスという単位で行います。このプロセスには幾つか状態があります。
- 実行状態:
そのプロセスにCPUが与えられ、本当の意味で実行されている状態。
この状態にあるプロセスは当然ながらCPUの数しかない。
- 実行可能状態:
プロセスがCPUを与えられることを待っている状態。
OSはこの状態のプロセスの中から、ある条件にしたがって ひとつ(or CPUの数だけ)を選び、実行状態にする。
- 休眠状態:
プロセスが寝ている状態で、CPUが与えられることはない。
sleep(usleep)で明示的に休眠することのほか、select での休眠、read/write などの関数のブロッキング(準備待ち)などで休眠状態に入り、休眠時間の経過やシグナルなどで実行可能状態に遷移する。
普段はこの3状態です。
さらに、実行状態には、ユーザ空間で実行している状態(普通にプログラムを実行)とカーネル空間で実行(システムコールを呼び出したとき)している状態があります。
プロセスを実行可能状態から実行状態にするための選択動作をスケジューリングといい、それを行う部分をスケジューラといいます。
この部分はマルチタスクOSとしての心臓部のひとつです。
別のプロセスにCPUを渡すということは、現在使っているプロセスからCPUの利用権を奪うことになります。これをプリエンプションといいます。
(一方、sleep は実行状態から休眠状態に自発的に遷移します。)
スケジューリングの選定条件
Linux のスケジューラは、カーネル空間のschedule()という関数が呼ばれることで動作します。
この関数内でプロセスの選定作業が行われ、必要なら別のプロセスに切り替えられます。
しばらくして、元のプロセスにCPUの利用権が戻ってきたときには、何事もなかったかのようにschedule()から return してきます。
面白いことに、各プロセスから見るとschedule()は「いつ帰ってくるか分からない 何もしない関数」に見えるのです。
さて、その選定条件ですが、基本的には
実行可能状態にあるプロセスの持ち時間にあたる数値を比較し、その数値が大きいプロセスにCPUを与える
ようになっています。
実際にはプロセスを切り替える手間を考慮して、直前までCPUを使っていたプロセスは少し有利、などのパフォーマンス向上のための味付けがしてあります。
この持ち時間は次に述べるタイマ割り込みのときにCPUを使用していたプロセスから減らしていきます。
つまりCPUを使い続けるようなプロセスはどんどん持ち時間が減り、結果的に時々実行可能状態になるようなプロセスより実質的な優先度が下になります。
それに対して、タイマ割り込みになる前に sleep などでCPUをOSに返してしまえば、CPUは使っていても持ち時間そのままなので、実行可能状態に戻れば、CPUをもらいやすいことになります。
ちなみに、実行可能状態にあるプロセスの持ち時間がすべて0になると持ち時間の再計算が行われます。それはすべてのプロセスに対して
という式で行われます。ここで c' は新しい持ち時間、c は現在の持ち時間、p はプロセスの優先順位を表す数値で、
nice コマンド、
nice()/setpriority()システムコール、により設定できる優先度に依存します。
この優先度1あたり、この再計算間隔で 10[ms]だけ余計にCPUがもらえるようになっています
(数字が大きいほど"nice"なので今回の目的にはなるべく小さくする)。
また、寝てばかりのプロセスではこの再計算を繰り返す結果、cは2pに漸近します。
これらのことから、
普段休眠していて、ときどき実行可能状態になるプロセスは
実行可能状態になった直後のスケジューリングでCPUを与えられやすい
といえます。もちろん、優先度が高いほど、より確実になります。
Linux とタイマ割り込み
Linux ではタイマ割り込みをつかって、内部で幾つかの処理を定期的に行っています。
この周期が多くのLinuxでは 10[ms]です。わかっている範囲で、 Alpha用のLinuxのみ 0.98[ms](1/1024[s]) です。
このタイマ割り込みで行う処理は
- Linux が内部で持ってる時間にかかわる変数の処理を行う
(jiffies, 時刻変数, load average など)
- 現在実行中のプロセスの持ち時間から1へらす
- 休眠中のプロセスの起床時間を確認して、時間になっていたら起こす
- その他、時間がきたら実行するよう、ドライバなどから依頼された処理をする
ことです。
Linuxによる一定周期実行の原理
上の2つの組合わせともうひとつのルールによって一定周期実行の原理が説明できます。
Linux の場合、
- ユーザ空間で実行中なら、割り込み処理終了後
- カーネル空間で実行中(システムコール実行中)なら、割り込み処理後システムコールを処理して、その後
- すべてのプロセスが休眠状態なら、どれかが実行可能状態になったとき
にスケジューラが呼ばれます。
(前2者の参考:
Linux2.2:arch/i386/kernel/entry.S , ret_with_reschedule, ret_from_intr)
つまり、タイマ割り込みで休眠プロセスが起こされたとき、
- なんらかのプロセスがユーザ空間で実行中なら、タイマ割り込み終了時にスケジューラによって持ち時間を比較し、
休眠していたプロセスの持ち時間が大きければ実行される
- なんらかのプロセスがカーネル空間で実行中に割り込みが発生したなら、システムコール終了後に同様な動作をする
- すべてのプロセスが休眠状態なら、即実行状態に移る
ことになります。
理想的には全プロセスが休眠しているか、現在実行状態のプロセスがユーザ空間で実行されていれば、一定時間 sleep しつつ動作するようなプログラムは、タイマ割り込みの精度(+カーネルの仕事時間)で周期的に実行されることになります。
システムコールが実行されている場合は、そのシステムコールの処理時間だけ遅れが発生します。
少し処理をして、タイマ割り込みが来る前 sleep で休眠するようなプロセスは、スケジューリングのところで述べたように、基本的に持ち時間は高くなっています。
その結果、CPUを得やすいわけです。その結果が上のグラフになります。
多少乱れが生じているのは、カーネルそのものタイマ割り込み時の処理量に変動があったり、システムコール中だったりするためと考えられます。
さて、タイマ割り込みで同時に複数のプロセスが実行可能状態になったら、どうなるでしょうか。
そのときはもちろん、持ち時間の多い方が優先です。
UNIXにおいては、多くのプロセスが走っていますが、実はそのほとんどが休眠状態です(サーバプロセスで要求町待機)。
つまり、目的の制御用に周期的に実行しているプロセスの他のプロセスが起きてしまったらそっちにCPUをとられる可能性があります。
CPUを得たプロセスが単純な処理ならいいのですが、最悪の場合は次のタイマ割り込みまでCPUが得られないということがあり得ます(それどころか、そのさき2〜3回ということも)。
この状態を回避するには、最初から持ち時間を多くしておくに限ります。具体的には
nice --20 a.out
とします。これは 優先度を20上げることを意味します(標準で0、-20が優先度最大、なので、これで最大になります)。
(数字が多いほどniceである、ということは-20というのはある意味極悪)
優先度は root でなければ負の値は設定できませんが、I/Oポートなどを操作しようと思ったら、やはり root でなければならないので、それはそれでよしとしましょう。
いっそのことプログラム中に
nice(-20);もしくは
setpriority(PRIO_PROCESS,0,-20);などと書いてしまうのもありです。
まとめ
一連の流れを整理します。
- プロセスが時間を指定して sleep で休眠する
- 指令された時間経過後のタイマ割り込みで起こされる
- タイマ割り込み直後(システムコール終了直後)のスケジューリングで実行可能状態に遷移。
- sleepから戻って制御処理を行い、初めにもどる
このような仕掛けによって、一見いいかげんなプログラムで、タイマ割り込みで量子化された周期で、周期的に処理を実行することが可能なのです。
この方法が、いい加減なように見えて期待通り動くのは、このようにOSの動作が都合良く設計されていたためですが、逆にOSの動作が
分かってしまったので、いい加減な方法ではなく、理論に基づいた手法となったのです。
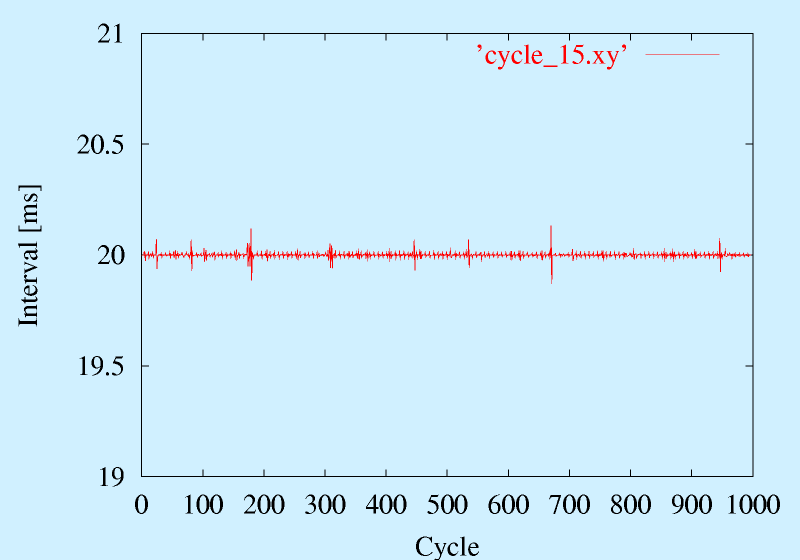 このプログラムは 引数を指定するとその時間([ms])だけ休むようになっています(
このプログラムは 引数を指定するとその時間([ms])だけ休むようになっています(